


Amazon Bedrock continues to be a fast-evolving service, and the latest addition, Amazon Bedrock AgentCore, has gone from its initial public preview launch in July 2025 to its general availability announcement in October 2025. Within the space of a quarter, AgentCore established itself as the 3rd option, between a fully managed Amazon Bedrock Agent on the one hand, and a bring-your-own-agent on the other hand.
Fully managed Amazon Bedrock Agents are great for teams that need to deliver fast, secure, and reliable agentic applications, enabling them to adopt abstractions in exchange for reduced control over the details. But for those who need more programmatic control of the agent or have existing investments, development history, and preferences for agent development frameworks, there was no middle ground… most of the heavy lifting was placed on those building production-level applications, including all the “-ilities”, such as observability, security, scalability, resiliency, and so on.
Enter Amazon Bedrock AgentCore.
Amazon Bedrock AgentCore is a managed “agentic platform” to which you can deploy your own agents at scale with the full flexibility and control of developing with your preferred agent framework, foundation model, or protocol. The AgentCore platform defines many of the primitives required by production workloads and run agents securely within Virtual Private Cloud (VPC), with access to tools and private data repositories, low-latency, and observability — all without any infrastructure management.
A good way to explore the new AgentCore service is to use the AI coding editor, Kiro, which is currently in public preview. The waiting list has recently been removed, and those who already have an Amazon Q Developer Pro subscription can sign in without the free tier. Equally, the Strands Agents SDK, a "code-first" framework for building agents, is a recent addition to the agent framework landscape. It places the reasoning abilities of the latest generation of foundation models, such as Athropic's Claude Haiku 4.5 and Claude Sonnet 4.5, and MCP tool calling, at the core of its framework to reduce the need for 'scaffolding' and extended system prompting.
The AWS Cloud Development Kit (AWS CDK), a software development framework for defining cloud services as code, now supports Amazon Bedrock AgentCore with the initial L1 Cfn resource constructs. The latest Terraform AWS Provider v6.16.0 does not yet support AgentCore resources, but it won't be long before they are available. We'll use a Jupyter notebook and the AWS SDK for Python (boto3 v1.40.52) to illustrate the building and deploying of agents into AgentCore Runtime.
For those on a tight time budget: The TL;DR of the following sections is to show how to set up Kiro, build an agent with the Strands Agent SDK with tool access to Amazon MCP servers and AWS Lakeformation resources, and deploy to the Amazon Bedrock AgentCore Runtime. Once deployed into the Runtime, the agent inherits essential properties such as Amazon VPC and PrivateLink networking security, AWS IAM authentication and authorisation, AWS CloudWatch and Open Telemetry-based observability, and gains access to additional features beyond the Runtime. Jump directly into the code, here.
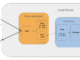
The diagram below illustrates the setup.

Note: This post focuses on AgentCore Runtime. AgentCore provides additional components, beyond the Runtime, i.e. AgentCore Identity, AgentCore Memory, AgentCore Gateway, and AgentCore Tools, which are covered in other posts.
Another note: The data lake architecture is presented in a separate post and won’t be repeated here. See On AWS CDK and Amazon Bedrock Agents for more information.
Let’s do it.
The notebook and snippets provide working code, with required substitutions shown in <>. To follow along, install the Kiro IDE, your favourite container runtime, UV or your favourite Python package manager, and the Strands Agents SDK.
Exploring with Kiro
Let's begin by setting up Kiro. One of the first things to do for our project is to set up Kiro's MCP servers and Steering (aka dev rules or guidelines). These settings are stored in the .kiro directory. They are applied at the user profile level or across the entire workspace, i.e. the entry directory in which Kiro was opened, including all of its subdirectories. The following snippet shows an initial set of documentation MCP servers that will ground the IDE on the latest documentation for Amazon Bedrock AgentCore and the Strands SDK.
{
"mcpServers": {
"strands-agents-docs": {
"command": "uvx",
"args": [
"strands-agents-mcp-server@latest"
],
"env": {
"FASTMCP_LOG_LEVEL": "ERROR"
},
"disabled": false,
"autoApprove": [
"mcp_strands_agents_search_docs",
"mcp_strands_agents_fetch_doc"
]
},
"awslabs.aws-documentation-mcp-server": {
"command": "uvx",
"args": [
"awslabs.aws-documentation-mcp-server@latest"
],
"env": {
"FASTMCP_LOG_LEVEL": "ERROR"
},
"disabled": false,
"autoApprove": [
"search_documentation",
"read_documentation"
]
},
"awslabs.amazon-bedrock-agentcore-mcp-server": {
"command": "uvx",
"args": [
"awslabs.amazon-bedrock-agentcore-mcp-server@latest"
],
"env": {
"FASTMCP_LOG_LEVEL": "ERROR"
},
"disabled": false,
"autoApprove": []
}
}
}
Adding documentation tools is particularly useful when developing against new or recently launched SDKs and libraries, as the underlying foundation models would not have been meaningfully trained on them. This saves you from passing URLs into prompts and generates better code that follows the appropriate SDK patterns. Equally, grounding the context with the various MCP documentation servers can make the more informal or exploratory exchanges in the chat panel more effective and extend the sense of flow, instead of breaking off into browser tabs to read online docs.
Sidebar: Asking Kiro in the chat panel to add these MCP servers to its settings will achieve the desired configuration without handling the JSON file.
Next, we set up our Steering or coding guidelines that Kiro should be following. Steering documents are files in markdown format, which Kiro automatically loads into its context. For example, define your preference for UV as the Python package manager, Ruff as the linter, standardise a specific project directory layout, use of other particular Python modules or which ones to avoid, define CI/CD standards, Dockerfile requirements, mandate the use of the Strands SDK documentation, and so on. These settings can turn Kiro into a pair programmer, a technique where two programmers work together at one workstation to write code. Equally, when dispatching or delegating work to Kiro, it will be aware of the required coding styles, tech stack requirements, and developer guidelines that need to be applied.
Sidebar: When working with existing projects, Kiro can scan the code base, discover the implicit developer rules and standards, and generate the first draft Steering documents, including product overviews and key features (product.md), workspace directory organisation, project patterns, file naming conventions, test structures, and more (structure.md), as well as the used technology stack, including programming languages, SDKs, build patterns, and development standards (tech.md).
When starting a new project or extending an existing one that goes beyond a ‘vibe-code’-level change, then Kiro's spec mode can come in. Especially when the aim is to work in an "agentic execution style" with production-level code as the goal, it is important to focus on structured methodology. This mode feels very natural and is aligned with an approach that many devs are already accustomed to, i.e. some sequence of reviewing or contributing to user stories and product requirements documents (PRD), then writing up some of the important design and tech choices, and finally putting together something akin to a notion page “to-do-list” or implementation task sequence. The task list can then, e.g. accommodate planning preferences, e.g. for a test-driven development approach. Once defined, Kiro loads the spec documents into its context during code generation. This, of course, is very different from one-shotting a prompt at an AI assistant and hoping for the best. Importantly, when working in dev teams, having some artefacts that capture the thought process, as opposed to a long chat history, is essential for effective collaboration.
The combination of tooling (MCP), steering (developer rules), and specs (work package), are the key components of context engineering, which help generate reliable code.
Kiro places the spec-driven approach at the centre of its IDE experience. These specs are living documents that can be efficiently maintained over time as the project progresses. Kiro’s agent hooks help streamline the development workflow by automatically executing predefined event-based agent actions, including routine tasks such as documentation and specs updates.
Sidebar: Kiro can also help generate the first draft of specs from an initial prompt that describes the work package or new feature. The generated specs include the requirement.md, design.md, and the tasks.md, which Kiro genrates, one after the other, iterating through a review process that is wired into the IDE.
To begin our project, a simple structure suitable for this purpose is shown below.
├──my_strands_agent
├── __init__.py
├── Dockerfile
├── docs
│ ├── mydocs.md
├── pyproject.toml
├── README.md
├── src
│ ├── __init__.py
│ ├── __main__.py
│ └── main.py
├── tests
└── uv.lock
Use ‘uv init my_strands_agent’ to set up the directory and initial files, ‘uv venv’ to create a Python virtual environment, and install the SDKs with ‘uv add strands-agents strands-agents-tools bedrock-agentcore mcp’. Install Python with ‘uv python install’ unless already present.
Finally, as we are coding on AWS, be sure to refresh the AWS credentials through environment variables or set up an AWS credentials file.
Now we're set up, and the following sections cover the walkthrough.
1. Defining the Strands Agent
The Strands Agents SDK is developer-friendly and supports the use of any model provider, including those hosted outside of Amazon Bedrock. The SDK delivers many foundational agent features, such as conversation and session memory management. Function decorators are included, such as @tools for defining our own special-purpose tools. The 'strands_tools' module additionally provides a library of general-purpose built-in tools like calculator, current_time, and use_aws, as well as an MCP client to readily extend the Strands agent capabilities with MCP servers.
The following snippet illustrates the use of these options in the main.py file for the agent.
"""
Strands Agent for Bedrock AgentCore deployment with AWS data processing capabilities.
Uses Strands SDK conversation manager for context management.
"""
from bedrock_agentcore.runtime import BedrockAgentCoreApp #Bedrock AgentCore SDK
from mcp import StdioServerParameters, stdio_client
from strands import Agent
from strands.agent.conversation_manager import SlidingWindowConversationManager
from strands.models import BedrockModel
from strands.tools.mcp import MCPClient
from strands_tools import current_time
# Initialize app
app = BedrockAgentCoreApp()
# Create model provider
bedrock_model = BedrockModel(
model_id="eu.anthropic.claude-sonnet-4-5-20250929-v1:0",
region_name=<AWS_REGION>,
temperature=0.1,
)
# System prompt
SYSTEM_PROMPT = """
ROLE:
- You are a data analysis agent. I use tools to retrieve and analyse data to answer user questions.
TOOL HINTS:
When using AWS Athena tools (manage_aws_athena_queries), ALWAYS include these parameters:
- result_configuration: {"OutputLocation": "s3://<my_output_bucket_name_hash>/athena-results/"}
- work_group: "primary"
- Use get-query-execution for obtaining results
- Always use actual table column names when generating sql queries
CONVERSATION BEHAVIOR:
- Be helpful and direct in responses
- Don't repeat introductions in ongoing conversations
"""
# MCP client for AWS data processing tools
mcp_client = MCPClient(
lambda: stdio_client(
StdioServerParameters(
command="/usr/local/bin/uvx",
args=[
"awslabs.aws-dataprocessing-mcp-server@latest",
"--allow-sensitive-data-access",
"--allow-write",
],
env={
"FASTMCP_LOG_LEVEL": "ERROR",
"AWS_REGION": <AWS_REGION>,
"AWS_DEFAULT_REGION": <AWS_DEFAULT_REGION>,
"ATHENA_DATABASE": <ATHENA_DATABASE>,
"ATHENA_WORKGROUP": <ATHENA_WORKGROUP>,
"ATHENA_OUTPUT_LOCATION": <ATHENA_OUTPUT_LOCATION>,
},
)
)
)
# Single agent instance with conversation management
# BedrockAgentCore handles session persistence, we just need context management for now
_agent = None
def get_agent():
"""Get or create the agent with conversation management"""
global _agent
if _agent is None:
# Create conversation manager to maintain context within conversations
conversation_manager = SlidingWindowConversationManager(
window_size=50, # Keep last 50 messages in context
should_truncate_results=True,
)
# Get tools from MCP server
tools = mcp_client.list_tools_sync()
# Create agent with conversation management (no session manager needed)
_agent = Agent(
tools=[tools, current_time],
model=bedrock_model,
system_prompt=SYSTEM_PROMPT,
conversation_manager=conversation_manager,
)
return _agent
@app.entrypoint
async def agent_invocation(payload):
"""Handler for agent invocation with conversation context management"""
user_message = (payload or {}).get("prompt", "Hello! You did not provide a prompt")
# Standard Strands SDK pattern - all operations within MCP context manager
with mcp_client:
# Get agent with conversation management
# BedrockAgentCore handles session persistence at runtime level
agent = get_agent()
# Using the standard Strands SDK streaming pattern
async for event in agent.stream_async(user_message):
# Standard pattern: only yield "data" events (text chunks). Ignore traces, etc...
if "data" in event:
yield event["data"]
if __name__ == "__main__":
app.run()
The first block imports our modules and defines the model provider as BedrockModel, indicating that we want to use a model that is hosted on Amazon Bedrock.
Sidebar: Many other model providers are supported, including OpenAIModel, MistralModel, and AnthropicModel for direct API access.
Then, provide the system prompt as a multi-line string, which again is very convenient as the SDK handles the model-specific syntax requirements of orchestration templates. Defining the stdio parameters for the MCPClient is the same as shown above for the MCP server up for Kiro. The Strands agent will be accessing the 'awslabs.aws-dataprocessing-mcp-server' to interact with a data lake that is fronted by the Athena SQL engine.
Sidebar: Alternatively, the agent could access the data lake through the ‘awslabs.ccapi-mcp-server’, which provides access to +1000 AWS cloud resource types.
Now we're ready to define the agent with the get_agent() function. The _agent is designed to prevent the creation of a new agent instance with each invocation, instead maintaining a conversation across multiple turns. Our agent is defined by a conversation manager, tools (tools, current_time), the system prompt, and the model.
The last block is the agent_invocation(payload) function. This is the programmatic entry point that invokes the agent, extracts the user message (payload) and streams the response.
Notice that the ‘with mcp_client’ pattern is required when defining Strands agents with MCP. This is one of the points to know, and when using Kiro to help with the agent development, then it will not get it right unless it loads the documentation into its context.
The @app.entrypoint decorator for the async agent_invocation function saves us from having to define our own HTTP API pattern, such as with FastAPI/Uvicorn. The Amazon Bedrock AgentCore SDK, which we imported as the bedrock_agentcore module at the top, provides us with the decorator. For those who need complete control of the API interface, they can do so by following a short set of AgentCore conventions.
2. Preparing deployment into AgentCore
At this point, we have defined the Strands agent and its HTTP API entrypoint. The next step is to containerise our agent in the same way as we would any other Python application and push to AWS Elastic Container Registry (ECR). The AgentCore Runtime exclusively accepts containerised agents, pulls the images from ECR, and then orchestrates the agent containers as a serverless runtime.
Sidebar: The Strands SDK team are providing a ‘Starter Toolkit’ to experiment with, that automates the containerisation and provisioning of AWS cloud resources. This is great for initial prototyping, but we’ll sidestep that and control these aspects directly.
The snippet below shows a Dockerfile, which begins by defining python:3.12-slim as our base image and sets our working directory on the container filesystem. Then the UV tools are installed, the pyproject.toml, which represents our dependencies, is copied into /app, and subsequently installed with' uv pip install –system'. Notice that the AWS Distribution for Open Telemetry (ADOT) module, which includes distributed tracing, metrics, and debugging, is also installed as a separate dependency with aws-opentelemetry-distro==0.12.1. The version pin is crucial as it contains type-handling fixes.
Then our agent application main.py is copied into the /app/src/ directory of the container image, port 8080 is exposed as per the requirements of AgentCore, and the container entrypoint CMD runs the agent Python module.
FROM public.ecr.aws/docker/library/python:3.12-slim
WORKDIR /app
# Install uv and uvx
COPY --from=ghcr.io/astral-sh/uv:0.9.3 /uv /uvx /usr/local/bin/
RUN chmod +x /usr/local/bin/uv /usr/local/bin/uvx
# Copy pyproject.toml and README.md for dependency installation (for better caching)
COPY pyproject.toml README.md ./
# Install system dependencies and Python packages in one layer
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
&& rm -rf /var/lib/apt/lists/* \
&& uv pip install --system --no-cache . \
&& uv pip install --system --no-cache aws-opentelemetry-distro==0.12.1
# Copy the rest of the application
COPY ./src ./src
# Set environment variables in one layer
ENV DOCKER_CONTAINER=1 \
PATH="/usr/local/bin:$PATH" \
PYTHONPATH="/app/src"
# Create non-root user
RUN useradd -m -u 1000 bedrock_agentcore
USER bedrock_agentcore
EXPOSE 8080
# Use the module path
CMD ["opentelemetry-instrument", "python", "-m", "main"]
The container image can now be built with e.g. docker buildx build — platform linux/arm64 -t {IMAGE_URI} –load, where the IMAGE_URI is the ECR registry name followed by the :tag. Notice that AgentCore requires arm64 container images and does not accept amd64.
Once the image is built and tagged, provision a private ECR registry with the chosen registry name, authenticate against ECR, and push the image as shown in the notebook.
3. Deploying into AgentCore Runtime
Now that we have our agent container image in ECR, we can provision AgentCore Runtime and add Runtime agents. As with many other AWS cloud resources, the Runtime agent requires an IAM execution role or service role to interact with AWS resources on our behalf. For example, the Runtime agent needs to access ECR, pull images, deliver logs into AWS CloudWatch Logs, and invoke Amazon Bedrock Models.
To do that, the obligatory AWS IAM entities and IAM permission policies are needed. Therefore, we provision an IAM role, attach both an 'assume role' or trust policy and a permission policy to the IAM role, and finally associate the role with the Runtime agent. The snippet below illustrates both.
permission_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock:*",
"bedrock-agentcore:*",
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogGroups",
"logs:DescribeLogStreams",
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage"
],
"Resource": "*"
}
]
}
# Define the trust policy for bedrock-agentcore.amazonaws.com
trust_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "bedrock-agentcore.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
The permission policy can also contain additional permissions, which is useful when using the built-in use_aws tool, which is essentially a comprehensive implementation of the boto3 library. This is a very flexible tool, and the IAM role permission policy can be used to apply access control constraints to AWS resources. For example, if the agent needed read-only access to a specific set of S3 buckets, then the applicable S3 permissions would be added to the policy.
Now we are ready to provision the Runtime Agent. The snippet below from the notebook cell defines a Runtime agent name, checks if one already exists under that name, and proceeds to provision it if not.
# Create new agent runtime
AGENT_RUNTIME_NAME = f"agent_core_notebook_{AWS_ACCOUNT_ID}"
EXECUTION_ROLE_ARN = str(role_arn)
# Check existing agent runtimes
print(f"🔍 Checking existing agent runtimes...")
try:
# List existing agent runtimes
response = agentcore_client.list_agent_runtimes()
for runtime in response.get('agentRuntimes', []):
if runtime['agentRuntimeName'] == AGENT_RUNTIME_NAME:
print(f"✅ Agent runtime already exists!")
except Exception as e:
try:
print(f"🚀 Creating agent runtime: {AGENT_RUNTIME_NAME}")
# Create agent runtime configuration
agent_runtime_config = {
'agentRuntimeName': AGENT_RUNTIME_NAME,
'description': f'GenAI AgentCore Runtime deployed from my notebook ',
'agentRuntimeArtifact': {
'containerConfiguration': {
'containerUri': FULL_IMAGE_URI
}
},
'roleArn': EXECUTION_ROLE_ARN,
'networkConfiguration': {
'networkMode': 'PUBLIC'
# Add networkModeConfig if using VPC mode
},
'protocolConfiguration': {
'serverProtocol': 'HTTP')
},
'environmentVariables': {
'PYTHONPATH': '/app/src',
'DOCKER_CONTAINER': '1'
}
}
response = agentcore_client.create_agent_runtime(**agent_runtime_config)
agent_runtime_arn = response['agentRuntimeArn']
agent_runtime_id = response['agentRuntimeId']
print(f"✅ Agent runtime created successfully!")
print(f" Runtime ARN: {agent_runtime_arn}")
print(f" Runtime ID: {agent_runtime_id}")
print(f" Status: {response['status']}")
print(f" Version: {response['agentRuntimeVersion']}")
except Exception as e:
print(f"❌ Failed to create agent runtime: {e}")
print(f" Troubleshooting:")
print(f" 1. Verify execution role exists: aws iam get-role --role-name {EXECUTION_ROLE_ARN.split('/')[-1]}")
print(f" 2. Check Bedrock AgentCore permissions")
print(f" 3. Verify image is accessible: aws ecr describe-images --repository-name {ECR_REPOSITORY_NAME}")
raise
The agent_runtime_config specifies the required elements to define an AgentCore agent, including the IAM role, container configuration, network configuration, protocol configuration, and environment variables.
The network configuration networkMode allows for public and private deployment. 'PUBLIC' deploys the agents into an environment with internet access, suitable for less sensitive or open-use scenarios, like ours. AgentCore Runtime can also host the agent container as a private resource within a VPC. In this case, the networkMode is set to 'VPC' and then the networkModeConfig is used to pass in additional information with the VPC ID, subnet ID, and security group ID.
The protocolConfiguration is interesting, as it designates what kind of containerised application is expected. With serverProtocol set to 'HTTP', the expectation is set for standard REST API interactions, which is precisely what is needed when, e.g. invoking an AgentCore hosted agent with an invoke_agent_runtime AWS SDK for Python call. However, AgentCore Runtime can also host agents intended for agent-to-agent (A2A) communications, enabling seamless collaboration between AI agents, rather than being invoked directly through a web API interface. Equally, AgentCore Runtime lets you deploy Model Context Protocol (MCP) servers, in which case the serverProtocol would be set to 'MCP'.
3. Use Kiro to generate a 'CLI tester'
Now that the agent is deployed into Runtime, we can invoke it from another Python application, e.g. by using the invoke_agent_runtime boto3 SDK call.
Generate a short Python script with Kiro. This is a small enough task that a quick vibe would generally have good results, which is excellent for rapid exploration and testing. Use the tester to initiate a conversation with a few turns, which are then captured by the "out of the box" observability features of AgentCore.
4. Monitoring the Runtime agent
By default, AgentCore outputs a set of built-in metrics and logs for its resources, including Runtime agents. Metrics and log data are automatically delivered into Amazon CloudWatch Metrics and CloudWatch Logs, respectively. The default metrics data include session and invocation counts, latency, duration, throttles, and various error rates. The logs capture the logger output from the containerised agent application, courtesy of the Bedrock AgentCore SDK (Python logging library).
Additionally, AgentCore can generate telemetry data in a standardised OpenTelemetry (OTEL / ADOT) format and deliver it to Amazon CloudWatch GenAI Observability for AgentCore. However, for Amazon CloudWatch to receive and process the incoming ADOT data, we must start indexing transaction spans by enabling X-Ray Transaction Search via Amazon CloudWatch settings.
Sidebar: This is why our Dockerfile contained instructions to install the ADOT package. For those who have been developing on AWS for some time, notice that the previously standalone X-Ray service is now integrated as part of the wider Amazon CloudWatch ecosystem.
Once X-Ray Transaction Search is enabled, all the GenAI Observability Agent dashboards will start to populate with data from ADOT-instrumented agents. The Agent View currently provides an activity overview derived from sampled spans, summarising agent-specific metrics such as total sessions, total collected traces, and errors, as well as Runtime metrics with vCPU and Memory resource consumption trends.
The Session View lists out the individual conversations and aggregated metrics, including the ones generated with the CLI tester. The Trace View panel provides the detailed span traces for each turn. This is where the detailed traces, timeline with latencies, and trajectory diagrams are shown.
Conclusions
Amazon Bedrock AgentCore is a serverless hosting layer for agents, aimed at teams that need to deploy and operationalise their own agentic workloads with fine-grained control over runtime, networking, and observability.
Developers can accelerate AI agents into production with the scale, reliability, and security critical to real-world deployment. Teams can build their own containerised agents based on any framework, such as Strands, LangChain, LangGraph, CrewAI, and deploy directly into a secure, serverless AgentCore Runtime. Compared to Amazon Bedrock Agents, which provide an abstracted and fully managed agent, AgentCore offers a hosted option for developers who work directly with Agent frameworks.
With native OpenTelemetry (ADOT) support, IAM-based execution roles, and CloudWatch GenAI Observability, AgentCore enables full-stack traceability and operational insight into deployed agents, helping reduce the undifferentiated heavy lifting.
This combination of controlled infrastructure and deep instrumentation establishes AgentCore as a cornerstone for scalable, compliant, and data-aware AI systems on AWS, with the option to extend agents using AgentCore Memory, Gateway, Identity, and Built-in-Tools. As the surrounding agent SDKs and cloud services converge, developers gain an increasingly unified and programmable platform for building intelligent, auditable, and resilient agentic applications.
The exploration with Kiro demonstrates how the new generation of development tools can codify agent specifications, enforce steering logic, and automate the grounding of MCP-based documentation for higher-quality code generation.
Appendix: Here is the notebook.
agent_core_notebook/agentecore_workflow_medium.ipynb at main · pipelineburst/agent_core_notebook

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories.
Subscribe to our newsletter and YouTube channel to stay updated with the latest news and updates on generative AI. Let’s shape the future of AI together!

On Kiro and Amazon Bedrock AgentCore Runtime was originally published in Generative AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source link

































Add comment