

SQL is the language of data; however, anyone who has spent some time writing queries knows the pain. Remembering exact syntax for window functions, multi-table joins, and debugging cryptic SQL errors can be tedious and time-consuming. For non-technical users, getting simple answers often requires calling in a data analyst. Large Language Models (LLMs) are starting to change this situation. Acting as copilots, LLMs can take human instructions and convert them into SQL queries, explain complex SQL queries to humans, and suggest optimizations for quicker computations. The results are clear: faster iterations, lower barriers for non-technical users, and less time wasted looking into syntax.
Why LLMs Make Sense for SQL
LLMs excel at mapping natural languages into structured texts. SQL is essentially structured text with well-defined patterns. Asking an LLM “Find the top 5 selling products last quarter,” and it can draft a query using GROUP BY (for various channels), ORDER BY, and LIMIT (to get top 5) clauses.
On top of drafting queries, LLMs can act as useful debugging partners. If a query fails, it can summarize the error, spot the faults in your input SQL, and recommend different solutions to fix it. They can also suggest more efficient alternatives to reduce computation time and increase efficiency. They can also translate SQL issues into plain English for better understanding.
Everyday Use Cases
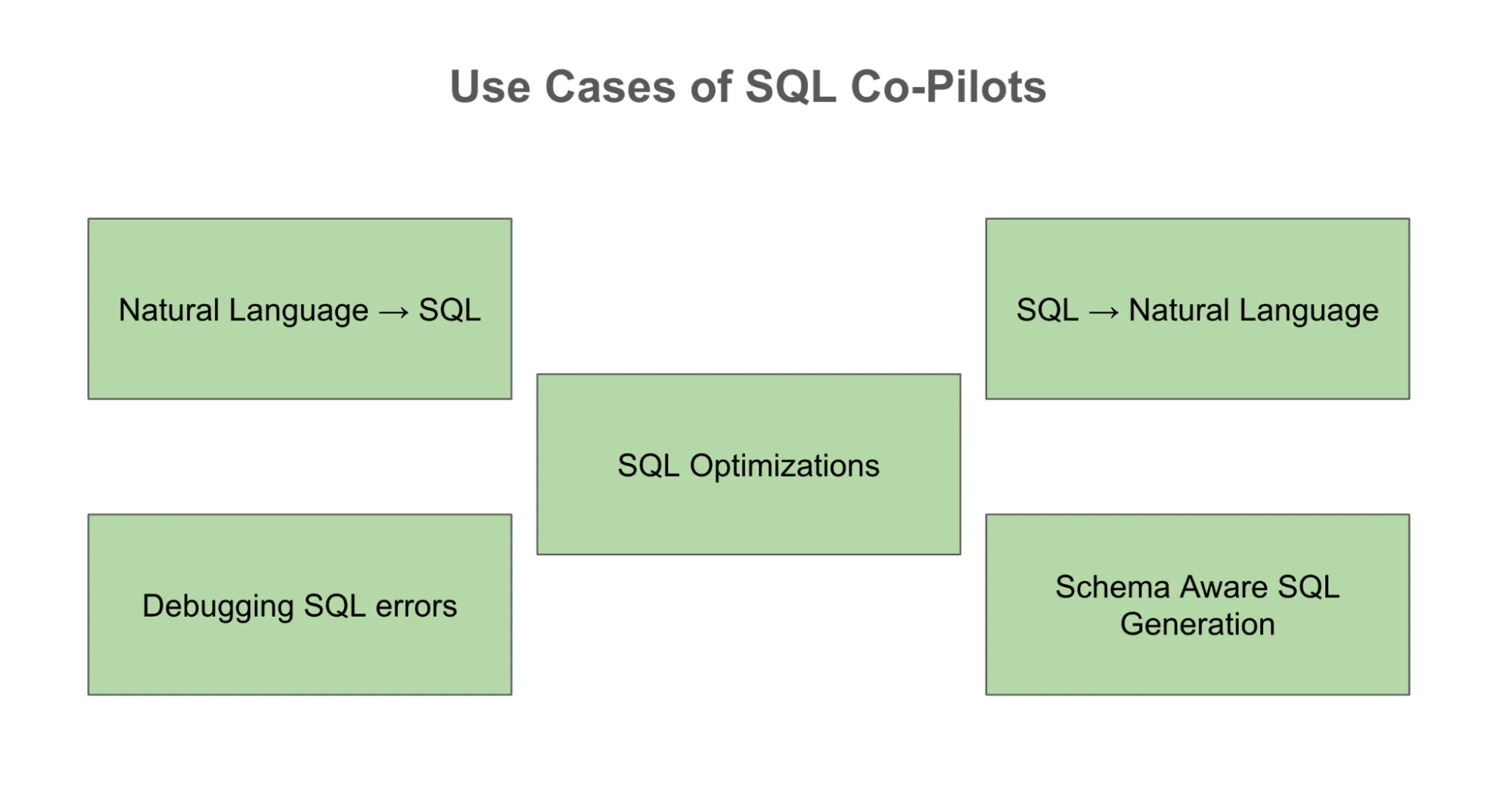
The most obvious use case is natural language to SQL, which allows anyone to express a business need and receive a draft query. But there are plenty of others. An analyst can paste an error code, and LLM can help debug the error. The same analyst can share the learnings on the correct prompts used to debug the error accurately and share them with fellow team members to save time. Newcomers can lean on the copilot to translate SQL into natural language. With the correct schema context, LLMs can generate queries tailored to the organization’s actual database structures, making them way more powerful than generic syntax generators.
Read more: Natural Language to SQL Applications
Copilot, Not Autopilot
Despite all their promise, LLMs also have some known limitations. The most prominent ones are column hallucination and generating random table names when not provided. Without a correct schema context, it is likely that LLM would resort to assumptions and get it wrong. The Queries generated by LLMs may execute, but they cannot be efficient, leading to increased costs and slower execution times. In addition to all of these issues, there is an obvious security risk as sensitive internal schemas would be shared with external APIs.
The conclusion is very straightforward: LLMs should be treated as copilots rather than depending on them completely. They can help draft and accelerate work, but human intervention will be needed for validations before executions.
Improving LLM Results through Prompt Engineering
Prompt engineering is one of the most crucial skills to learn to use LLMs effectively. For SQL copilots, prompting is a key lever as vague prompts can often lead to incomplete, wrong, and sometimes senseless queries. With correct schema context, table column information, and description, the quality of the output query can increase dramatically.
Along with data schema information, SQL dialect also matters. All SQL dialects like Postgres, BigQuery, and Presto have small differences, and mentioning the SQL dialect to the LLM will help avoid syntax mismatches. Being detailed about output also matters, for eg: Specify date range, top N users, etc, to avoid incorrect results and unnecessary data scans (which can lead to expensive queries).
In my experience, for complex queries, iterative prompting works the best. Asking the LLM to build a simple query structure first and then refining it step by step works the best. You can also use the LLM to explain its logic before giving you the final SQL. This is useful for debugging and teaching the LLM to focus on the right topics. You can use Few-shot prompting, where you show the LLM an example query before asking it to generate a new one, so that it has more context. Finally, error-driven prompting helps the end user debug the error message and get a fix. These prompting strategies are what make the difference between queries that are “almost correct” and the ones that actually run.
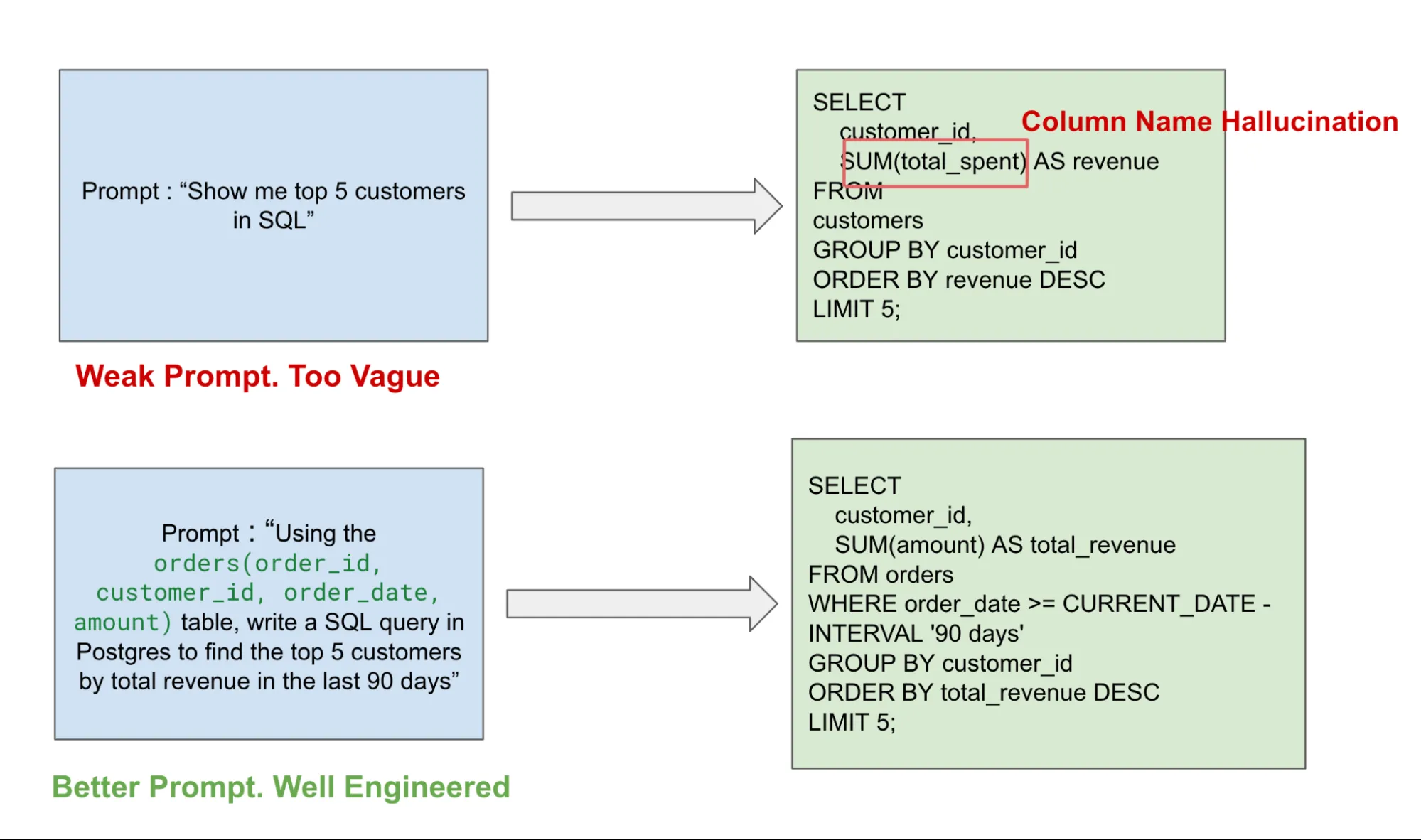
You can see this in the example below, where a vague prompt leads to column name hallucination. Compared to a well-engineered and more detailed prompt, you get a well-defined query matching the required SQL dialect without any hallucination.
Best Practices for LLMs as SQL copilots
There are some best practices that one can follow while using a SQL Copilot. It’s always preferred to manually review the query before running, especially in a production environment. You should treat LLM outputs as drafts rather than the actual output. Secondly, integration is key, as a Copilot integrated with the organization’s existing IDE, Notebooks, etc., will make them more usable and effective.

Guardrails and Risks
SQL Copilots can bring huge productivity gains, but there are some risks we should consider before rolling them out organization-wide. Firstly, the concern is around over-reliance; Copilots can lead to Data Analysts relying heavily on it and never building core SQL knowledge. This can lead to potential skills gaps where teams can create SQL prompts but cannot troubleshoot them.
Another concern is around the governance of data. We need to make sure copilots do not share sensitive data with users without correct permissions, preventing prompt injection attacks. Organizations need to build the correct data governance layer to prevent information leakage. Lastly, there are cost implications where Frequent API calls to Copilots can lead to costs adding up quickly. Without correct usage and token policies, this can cause budget issues.
Evaluation Metrics for Copilot Success
An important question while investing in LLMs for SQL Copilots is: How do you know they are working? There are multiple dimensions in which you can measure the effectiveness of copilots, like correctness, human intervention rate, time saved, and reduction in repetitive support requests. Correctness is an important metric to help determine, in cases where SQL Copilot is providing a query that runs without errors, does it produces the right expected result. This can be achieved by taking a sample of inputs given to Copilot and having analysts draft the same query to compare outputs. This will not only help validate Copilot results but can also be used to improve prompts for more accuracy. On top of this, this exercise will also give you the estimated time saved per query, helping quantify the productivity boost.
Another simple metric to consider is % of generated queries that run without human edits. If Copilot consistently produces working runnable queries, they are clearly saving time. A less obvious but powerful measure would be a reduction in repeated support requests from non-technical staff. If business teams can self-serve more of their questions with copilots, data teams can spend less time answering basic SQL requests and focus more time on quality insights and strategic direction.
The Road Ahead
The potential here is very exciting. Imagine copilots who can help you with the whole end-to-end process: Schema-aware SQL generation, Integrated into a data catalog, capable of producing dashboards or visualizations. On top of this, copilots can learn from your team’s past queries to adapt their style and business logic. The future of SQL is not about replacing it but removing the friction to increase efficiency.
SQL is still the backbone of the data stack; LLMs, when working as copilots, will make it more accessible and productive. The gap between asking a question and getting an answer will be dramatically reduced. This will free up analysts to spend less time wrangling and googling syntaxes and more time developing insights. Used wisely with careful prompting and human oversight, LLMs are poised to become a standard part of the data professional’s toolkit.
Frequently Asked Questions
A. They turn natural language into SQL, explain complex queries, debug errors, and suggest optimizations—helping both technical and non-technical users work faster with data.
A. Because LLMs can hallucinate columns or make schema assumptions. Human review is essential to ensure accuracy, efficiency, and data security.
A. By giving clear schema context, specifying SQL dialects, and refining queries iteratively. Detailed prompts drastically reduce hallucinations and syntax errors.
Madhura Raut is a Principal Data Scientist at Workday, where she leads the design of large-scale machine learning systems for labor demand forecasting. She is the lead inventor on two U.S. patents related to advanced time series techniques, and her ML product has been recognized as a Top HR Product of the Year by Human Resource Executive. Madhura has been keynote speaker at many prestigious data science conferences including KDD 2025 and has served as judge and mentor to multiple codecrunch hackathons.
Login to continue reading and enjoy expert-curated content.
Source link

































Add comment