

Over the last few years, Prompt engineering has been the secret handshake of the AI world. The right phrasing could make a model sound poetic, funny, or insightful; the wrong one turned it flat and robotic. But a new Stanford-led paper argues that most of this “craft” has been compensating for something deeper, a hidden bias in how we trained these systems.
Their claim is simple: the models were never boring. They were trained to act that way.
And the proposed solution, called Verbalized Sampling, might not just change how we prompt models; it could rewrite how we think about alignment and creativity in AI.
The Core Problem: Alignment Made AI Predictable
To understand the breakthrough, start with a simple experiment. Ask an AI model, “c” Do it five times. You’ll almost always get the same response:

This isn’t laziness; it’s mode collapse, a narrowing of the model’s output distribution after alignment training. Instead of exploring all the valid responses it could produce, the model gravitates toward the safest, most typical one.
The Stanford team traced this to typicality bias in the human feedback data used during reinforcement learning. When annotators judge model responses, they consistently prefer text that sounds familiar. Over time, reward models trained on that preference learn to reward normality instead of novelty.
Mathematically, this bias adds a “typicality weight” (α) to the reward function, amplifying whatever looks most statistically average. It’s a slow squeeze on creativity, the reason most aligned models sound alike.
The Twist: The Creativity Was Never Lost
Here’s the kicker: the diversity isn’t gone. It’s buried.
When you ask for a single response, you’re forcing the model to pick the most probable completion. But if you ask it to verbalize multiple answers along with their probabilities, it suddenly opens up its internal distribution, the range of ideas it actually “knows.”
That’s Verbalized Sampling (VS) in action.
Instead of:
Tell me a joke about coffee
You ask:
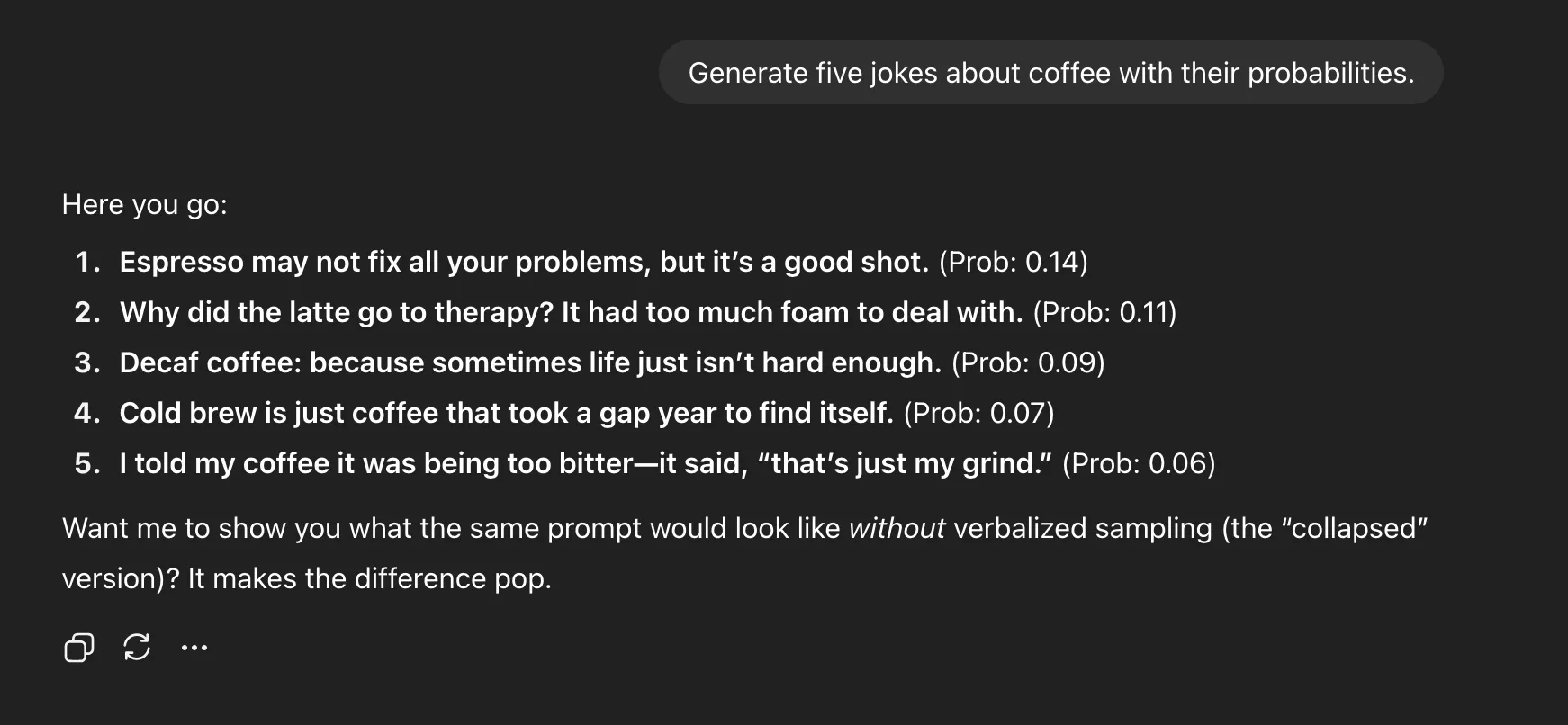
Generate five jokes about coffee with their probabilities
This small change unlocks the diversity that alignment training had compressed. You’re not retraining the model, changing temperature, or hacking sampling parameters. You’re just prompting differently—asking the model to show its uncertainty rather than hide it.
The Coffee Prompt: Proof in Action
To demonstrate, the researchers ran the same coffee joke prompt using both traditional prompting and Verbalized Sampling.
Direct Prompting
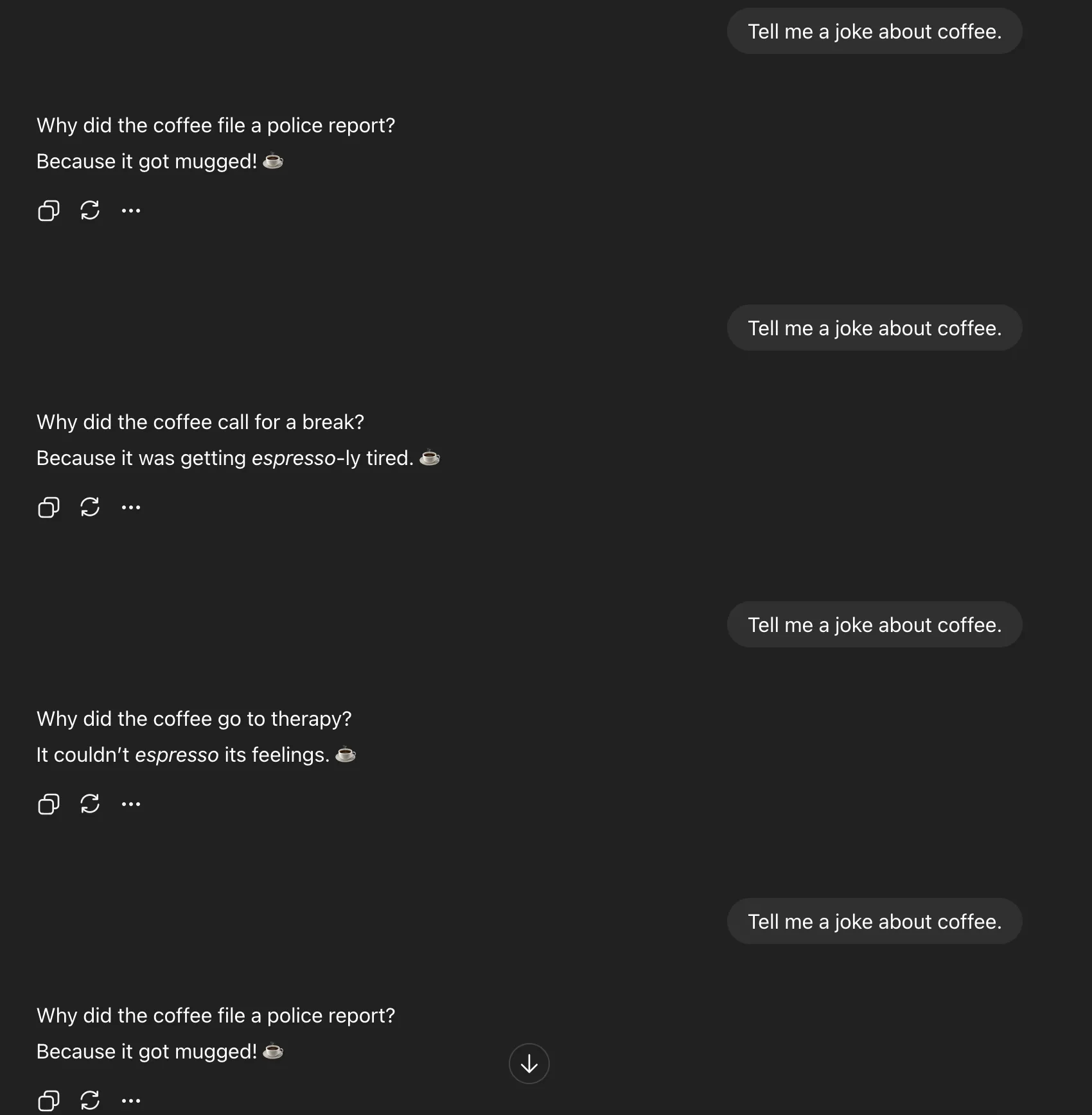
Verbalized Sampling
Why It Works
During generation, a language model internally samples tokens from a probability distribution, but we usually only see the top choice. When you ask it to output several candidates with probabilities attached, you’re making it reason about its own uncertainty explicitly.
This “self-verbalization” exposes the model’s underlying diversity. Instead of collapsing to a single high-probability mode, it shows you several plausible ones.
In practice, that means “Tell me a joke” yields one mugging pun, while “Generate five jokes with probabilities” produces espresso puns, therapy jokes, cold brew lines, and more. It’s not just variety, it’s interpretability. You can see what the model thinks might work.
The Data and the Gains
Across multiple benchmarks, creative writing, dialogue simulation, and open-ended QA, the results were consistent:
- 1.6–2.1× increase in diversity for creative writing tasks
- 66.8% recovery of pre-alignment diversity
- No drop in factual accuracy or safety (refusal rates above 97%)
Larger models benefited even more. GPT-4-class systems showed double the diversity improvement compared to smaller ones, suggesting that big models have deep latent creativity waiting to be accessed.
The Bias Behind It All
To confirm that typicality bias really drives mode collapse, the researchers analyzed nearly seven thousand response pairs from the HelpSteer dataset. Human annotators preferred “typical” answers about 17–19% more often, even when both were equally correct.
They modeled this as:
r(x, y) = r_true(x, y) + α log π_ref(y | x)
That α term is the typicality bias weight. As α increases, the model’s distribution sharpens, pushing it toward the center. Over time, this makes responses safe, predictable, and repetitive.
What does it mean for Prompt Engineering?
So, is prompt engineering dead? Not quite. But it’s evolving.
Verbalized Sampling doesn’t remove the need for thoughtful prompting—it changes what skillful prompting looks like. The new game isn’t about tricking a model into creativity; it’s about designing meta-prompts that expose its full probability space.
You can even treat it as a “creativity dial.” Set a probability threshold to control how wild or safe you want the responses to be. Lower it for more surprise, raise it for stability.
The Real Implications
The biggest shift here isn’t about jokes or stories. It’s about reframing alignment itself.
For years, we’ve accepted that alignment makes models safer but blander. This research suggests otherwise: alignment made them too polite, not broken. By prompting differently, we can recover creativity without touching the model weights.
That has consequences far beyond creative writing—from more realistic social simulations to richer synthetic data for model training. It hints at a new kind of AI system: one that can introspect on its own uncertainty and offer multiple plausible answers instead of pretending there’s only one.
The Caveats
Not everyone’s buying the hype. Critics point out that some models may hallucinate probability scores instead of reflecting true likelihoods. Others argue this doesn’t fix the underlying human bias, it simply sidesteps it.
And while the results look strong in controlled tests, real-world deployment involves cost, latency, and interpretability trade-offs. As one researcher dryly put it on X: “If it worked perfectly, OpenAI would already be doing it.”
Still, it’s hard not to admire the elegance. No retraining, no new data, just one revised instruction:
Generate five responses with their probabilities.
Conclusion
The lesson from Stanford’s work is bigger than any single technique. The models we’ve built were never unimaginative; they were over-aligned, trained to suppress the diversity that made them powerful.
Verbalized Sampling doesn’t rewrite them; it just hands them the keys back.
If pretraining built a vast internal library, alignment locked most of its doors. VS is how we start asking to see all five versions of the truth.
Prompt engineering isn’t dead. It’s finally becoming a science.
Frequently Asked Questions
A. Verbalized Sampling is a prompting method that asks AI models to generate multiple responses with their probabilities, revealing their internal diversity without retraining or parameter tweaks.
A. Because of typicality bias in human feedback data, models learn to favor safe, familiar responses, leading to mode collapse and loss of creative variety.
A. No. It redefines it. The new skill lies in crafting meta-prompts that expose distributions and control creativity, rather than fine-tuning single-shot phrasing.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.
Login to continue reading and enjoy expert-curated content.
Source link


































Add comment