
We have been hearing the term AGI for a while now. However, the majority of the best-performing LLMs are still not very adept at resolving challenging problems, let alone reaching AGI. These are some issues that take a lot of time and effort to resolve, even for us humans. To solve such complex puzzles, we must be able to identify patterns, generate abstract knowledge, and improve our reasoning with each iteration. We will now read about a model known as the “Hierarchical Reasoning Model,” which has gained attention in the field of AI research and outperformed several well-known LLMs, including GPT-5, Deepseek R1, Claude’s Opus 4, and OpenAI’s o3 model. This article will go over what HRMs are and why they are pushing the envelope when it comes to AGI.
The Current Problem
For tasks requiring reasoning, almost all of the transformer models in use today rely on CoT (Chain of Thought). Here, we’ll be giving the model input, and it will produce relevant tokens that demonstrate the natural language reasoning process (similar to the one we see in DeepSeek). This process continues until it comes to a final point. The cost for generating such a lengthy thought trace is also higher because iterating repeatedly and making multiple forward passes increases the context window, which slows down the process while consuming a lot of data.
By breaking down the problem into smaller intermediate steps, these natural language reasoning steps allow the model to perform multi-step complex reasoning. But there is also a significant disadvantage to this type of Tree of Thought reasoning process. If an error is made at the beginning or in the middle of the process, it may propagate to the following stages and result in the incorrect answer being outputted.
Read more: Chain-of-Though Prompting
What’s going on
The majority of processes have this type of architecture, in which the model can include multiple transformer blocks. As is widely recognised, each block is essentially a typical causal attention-based transformer which combines multi-head attention with RoPE embeddings. a feed-forward network, normalisation layers, and residual connections.
The plot above compares the performance of transformers as their sizes are increased, first by scaling the width and then by scaling the depth with extra layers. This demonstrates the significant advantages of greater depth. However, after a certain number of parameters, transformer performance does not increase or saturate from this increased depth.
So, there was a particular solution to this issue. Here, we’ll be applying the recurrent network. By using recurrent blocks, we can efficiently achieve arbitrary depth in this recurrent network architecture, where each block reuses the same set of parameters. since numerous steps are involved in the same computation. Nonetheless, the model may progressively lose awareness of our problem statement as the hidden representations are modified over several iterations (similar to catastrophic forgetting).
Our model must understand the initial input to combat this issue. This can be accomplished, for example, by injecting the embedded input data into each iteration’s recurrent block. This is also called recall or input injection in loop transformers. This makes it easier to stay fully aware of the original context of the problem while using reasoning.
We can see here how recurrent-based transformers work better than traditional transformers. We also get to see that by increasing the number of iterations in the recurrent network, performance eventually drops as the models get deeper.
Now we have understood the previous issues we encountered when it comes to reasoning-based tasks. Now, let’s jump into how HRMs work and counter these shortcomings.
What is HRM?
HRM was inspired by biology, as the human brain has a cross-frequency that couples between theta and gamma neural frequencies. Its dual recurrent loop system is HRM’s main innovation. Based on the probability of the subsequent word from earlier tokens, normal transformers are made to predict the next token. In contrast, two different recurrent neural networks are used by HRM to generate tokens.
Here, the HRM is going to engage in a cognitive process by thinking quickly at lower levels while also receiving guidance from higher levels that are slower and more abstract than the lower levels. This is essentially the inspiration that is primarily biology-oriented. In the following section, we will understand the technical understanding of HRMs.
The HRM architecture divides the thought process into two branches, as in the inspiration above, which employs two distinct time frequencies that can affect one’s thought bursts, ensuring higher reasoning.
HRM Internals
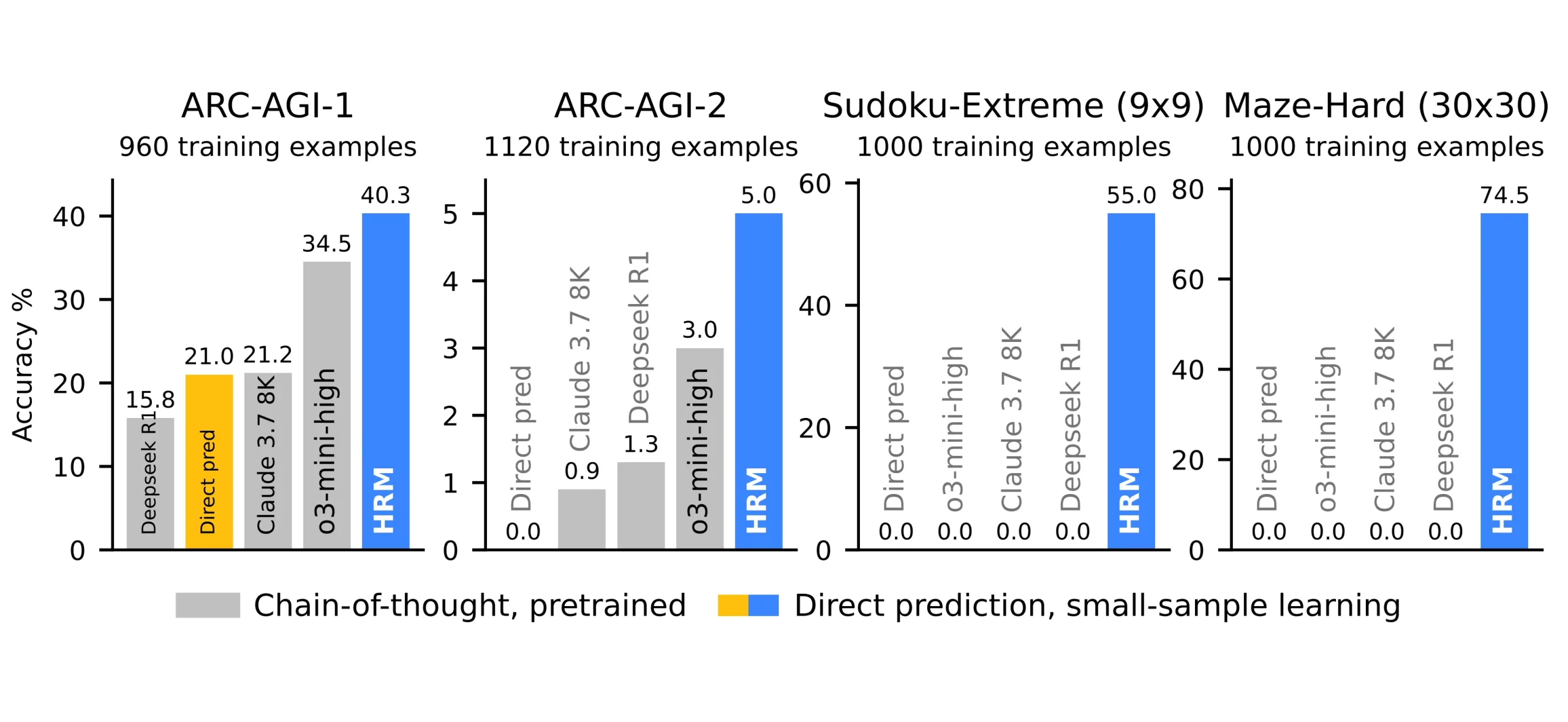
HRM didn’t do any pre-training in the current case. When creating an LLM, pretraining is typically an essential step in which the model is fed billions to trillions of data points to learn from. These models that we previously used are referred to as foundational models. Here, HRMs are not foundation models.
Since HRMs are unable to generalise on tasks, they are unable to generalise from vast amounts of data as foundational models do. Instead, ARC-AGI measures its capacity for intuition and the ability to solve logical puzzles. Reinforcement learning (Q-learning) is used to train this HRM mechanism. If the model stops at the appropriate moment and generates the correct response, it is rewarded.
Here, HRM adopts a totally different strategy that makes use of both the input injection component and the best features of the recurrent network architecture. In this case, the model only prints the final response without the reasoning traces, carrying out the entire reasoning process internally in a single forward pass.
HRM here makes use of 2 recurrent modules:-
- H module: Used for high-level abstract reasoning and planning.
- L module: Used for fast, detailed computations
Both of these 2 modules are coupled with each other and work together in the reasoning process.
Note:- Both the H and L modules are recurrent networks, each with a unique set of parameters or weights.
HRM Workflow
Now, let’s understand the workflow of HRM.
The input is first transformed into machine-readable form by the trainable embedding layer. The two coupled recurrent modules, which operate at various time frequencies, are then used by the HRM. The planner is a high-level module that manages abstract reasoning and defines the general course. The low-level module is the doer; it follows the high-level plan by performing quick, complex calculations.
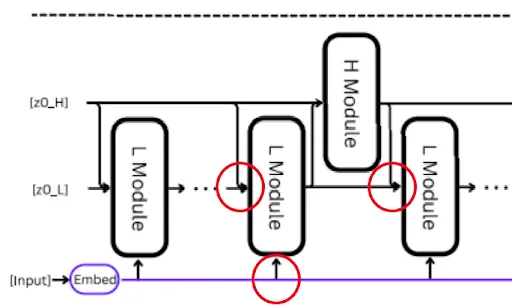
The low-level module starts working first. As it takes the input embedding s and the initial hidden states of both the low-level and high-level modules (z0_H and z0_L), and then updates its hidden state. It then runs several recurrent steps on each; it consumes its hidden state from the previous step along with the input embeddings, along with the hidden state from the high-level module, which is the first one since it hasn’t run yet.
The low-level modules run for T steps. Once done, its hidden state is sent up to the high-level module. The high-level module processes it along with its own previous hidden state and updates its plan accordingly, and sends a new high-level hidden state back down to the low-level module.
The low-level module again runs for another T steps, now with a new hidden state input from the high-level module, and sends the result back up. This is basically a nested loop for N cycles of low-level modules until the model converges. Here, convergence means we arrive at the final answer from both the high-level and low-level modules. Finally, the last high-level hidden state is fed to a trainable output layer that produces the final tokens. So basically, low-level modules run for N*T times, where N is the number of times the high-level module.
Simple Understanding
The low-level module takes several quick steps to reach a partial solution. That result is sent up to the high-level module, which then updates the plan. The low-level module resets and runs again for T steps, and the cycle repeats for N times until the model converges on the final answer.
def hrm(z, x, N=2, T=2):
x = input_embedding(x)
zH, zL = z
with torch.no_grad():
for _i in range(N * T - 1):
zL = L_net(zL, zH, x)
if (_i + 1) % T == 0:
zH = H_net(zH, zL)
# 1-step grad
zL = L_net(zL, zH, x)
zH = H_net(zH, zL)
return (zH, zL), output_head(zH)
# Deep Supervision
for x, y_true in train_dataloader:
z = z_init
for step in range(N_supervision):
z, y_hat = hrm(z, x)
loss = softmax_cross_entropy(y_hat, y_true)
z = z.detach()
loss.backward()
opt.step()
opt.zero_grad()As is well known, recurrent networks frequently encounter early convergence, meaning they conclude after a certain number of steps. This issue is resolved, and computational depth is attained through the interaction of two HRM modules. The high-level module’s update functions as a planner when the low-level module begins to converge, resetting the convergence. In contrast to conventional recurrent networks, this enables HRM to achieve a higher computational depth.
How are HRMs trained?
Backpropagation through time (BPTT) is typically used to train models of recurrent neural networks. The loss is then back-propagated through each step, requiring a significant amount of memory and frequently becoming unstable as the chain of reasoning grows longer. HRM uses a one-step gradient approximation to get around this issue.
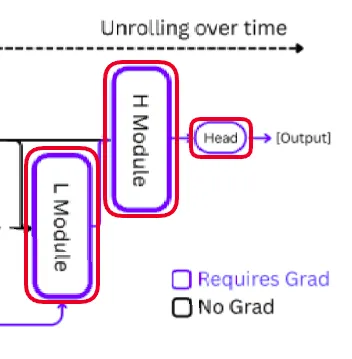
There are some benefits we get by doing this:-
- No matter how many reasoning steps are done, the memory will remain the same.
- There is training stability since it avoids exploding and vanishing gradients issues from backpropagation chains
There are a number of particular challenges when training this type of model when we repeatedly iterate the recurrent blocks. Because it eliminates the need for unrolled computation over time, this logic significantly lowers memory usage. Every pass is referred to as a segment. The application of Deep Supervision is suggested in the paper. In other words, each segment’s gradients are kept from reverting to their earlier states. In this way, the model uses a one-step gradient approximation in the setting of recursive deep supervision.
Observation
Another point to note is that, in contrast to what the previous images show, the high-level module’s final hidden state is not sent straight into the output layer. However, it goes through a halting headfirst, which determines whether the model should stop or continue for another N cycle, much like humans do when we look back and determine whether we made the right choice. Depending on the task, the model can dynamically modify its thinking time. In general, more cycles of reasoning will be required for harder problems.
Conclusion
The recent development of Hierarchical Reasoning Models (HRMs) represents an important development in our understanding of AI reasoning. HRMs demonstrate that effective reasoning can be accomplished through structured recurrence inspired by the human brain. These models demonstrate that RNN-style thinking still has a place in contemporary AI by combining high-level planning with quick low-level computation. They also outperform some of the most sophisticated LLMs available today and bring back the long-overlooked potential of recurrent architectures.
This “return of recurrence” indicates a time when reasoning systems will be more compact, quicker, and flexible, able to dynamically modify their level of detail to correspond with task complexity. HRMs exhibit exceptional problem-solving skills in logical and navigation tasks, but they do not rely on extensive pretraining like foundation models do. HRMs and their recurring backbone might define the next phase of AGI research, bringing us one step closer to AI that thinks more like humans, if transformers defined the previous one.
Read more: Future of LLMS
Frequently Asked Questions
A. Unlike transformers that rely on chain-of-thought traces, HRMs use two coupled recurrent modules—one for fast computations and one for high-level planning—allowing efficient reasoning without massive pretraining.
A. HRMs reset convergence through high-level planning updates, preventing early collapse and allowing deeper reasoning compared to standard recurrent networks.
A. They achieve strong reasoning performance with just 27M parameters and 1,000 training examples, using one-step gradient approximation to avoid the high memory costs of backpropagation through time.
GenAI Intern @ Analytics Vidhya | Final Year @ VIT Chennai
Passionate about AI and machine learning, I’m eager to dive into roles as an AI/ML Engineer or Data Scientist where I can make a real impact. With a knack for quick learning and a love for teamwork, I’m excited to bring innovative solutions and cutting-edge advancements to the table. My curiosity drives me to explore AI across various fields and take the initiative to delve into data engineering, ensuring I stay ahead and deliver impactful projects.
Login to continue reading and enjoy expert-curated content.
Source link
































Add comment